chat_raw <- readLines("epl-chat.txt")Text analysis of whatapp group chats
text-analysis
I recently began to read the “Text Mining with R” book from by Julia Silge and David Robinson. I thought I would apply this knowledge to my Whatapp group chats
Exporting the data
Whatsapp allows you to export chats to a text file. For long running, or message intensive chats this does not always work - Whatapp sucks sometimes. I was fortunate enough to be able to export my group chat that begun in Janurary 2023. Furthermore, you can export with or without media. Since I was doing a text analysis, I chose to export without media.
Within whatapp on my phone, I went to the group chat > chat options (3 vertical dots) > more > Export chat > Without media, and exported the chat to my my googledrive. I then copied the file to my project directory.
epl-chat.txtThe data
The data is a text file with each line a message from the chat. We use readLines() to import it into R
There were 27308 messages in this file
length(chat_raw)[1] 27308The general structure of the messages are
- timestamp
- name
- message text
Note: there are some messages that do not follow this structure and they are messages involved with the chat setup e.g. “Person added you” or “Person left the chat”, or when there are multi-line messages, or for some other reason.
head(chat_raw)[1] "5/1/23, 3:54 am - Messages and calls are end-to-end encrypted. No one outside of this chat, not even WhatsApp, can read or listen to them. Tap to learn more."
[2] "5/1/23, 3:54 am - Gerrard created group \"Real EPL Chat\""
[3] "5/1/23, 3:54 am - Gerrard added you"
[4] "5/1/23, 3:54 am - Gerrard changed this group's icon"
[5] "5/1/23, 3:55 am - Gerrard: Putting the other chat on Mute and seeing how it takes for the English to notice"
[6] "5/1/23, 3:56 am - Gerrard: Think we should have a catch over a game sometime, it's been a long while for some of us" Data wrangling
Packages
We use tidyverse packages dplyr, tidyr and ggplot2 as well as tidytext, emoji and wordcloud packages.
library(dplyr)
library(tidyr)
library(tidytext)
library(emoji)
library(ggplot2)
library(wordcloud)Fix multi-line messages
When there is a newline character in a message i.e. a message with multple lines, it will create a new line in the exported chat. We want all the text from a message to be on one line, and in-line with the timestamp and name.
For example
# Output lines 2:4 are from the same message
chat_raw[123:127][1] "30/1/23, 11:02 am - Gerrard: Hungover and typical emo professional sportsmen"
[2] "30/1/23, 11:26 am - Jono: https://twitter.com/skysportsnews/status/1620004706159296519?s=48&t=Dltf9xxkoAIEO9BGNlNHWw "
[3] ""
[4] "The replies lol"
[5] "31/1/23, 11:29 am - Gerrard: <Media omitted>" We can identify where these occur by checking if the line begins with a date
# Return row indices of lines not starting with a date
starts_with_1_or_2_digits <- '^[[:digit:]]{1,2}/'
not <- function(x){ !x }
multiline_msgs <-
grepl(pattern = starts_with_1_or_2_digits, x = chat_raw) |>
not() |>
which()
# Note 125, 126 and 825, 826 are each part of multi-line messages
head(multiline_msgs)[1] 125 126 307 825 826 828The root message of these is then the index - 1 (the previous message)
# 124 with 125, 126
chat_raw[124:126][1] "30/1/23, 11:26 am - Jono: https://twitter.com/skysportsnews/status/1620004706159296519?s=48&t=Dltf9xxkoAIEO9BGNlNHWw "
[2] ""
[3] "The replies lol" # 824 with 825, 826
chat_raw[824:826][1] "13/7/23, 12:35 pm - Jono: https://twitter.com/utdfaithfuls/status/1679411517538594816?s=48"
[2] ""
[3] "Pretty fucking crazy" Joining multi-line messages
The algorithm to fix these would be to
- start at the last index and paste that text with the index - 1 text (the previous message)
- repeat for all multi-line indices
- finally, remove multi-line indices
chat_raw_single <- chat_raw
for(curr_msg_ind in rev(multiline_msgs)){
# Paste with previous message
prev_msg_ind = curr_msg_ind - 1
chat_raw_single[prev_msg_ind] <-
paste(chat_raw_single[prev_msg_ind],
chat_raw_single[curr_msg_ind])
# Finally remove mutli-line messages
if (curr_msg_ind == multiline_msgs[1]) {
chat_raw_single <-
chat_raw_single[-multiline_msgs]
}
}chat_raw_single[124][1] "30/1/23, 11:26 am - Jono: https://twitter.com/skysportsnews/status/1620004706159296519?s=48&t=Dltf9xxkoAIEO9BGNlNHWw The replies lol"chat_raw_single[821] # index lower since we removed lines[1] "13/7/23, 12:35 pm - Jono: https://twitter.com/utdfaithfuls/status/1679411517538594816?s=48 Pretty fucking crazy"Parse text data
The first goal is to split the messages into a 3-column data.frame by:
- timestamp
- name
- message text
The timestamp is separated from the name and text components with -, and the name is separated from the text with a :.
Split time from name-text
Note: if - is found anywhere else in the message line, then it will create additional splits.
chat_split_raw <-
chat_raw_single |>
strsplit(split = ' - ')This should return a large list of lists, each with 2 elements - the timestamp and the name-text.
chat_split_raw[10:12][[1]]
[1] "5/1/23, 3:58 am" "Gerrard: Added JD"
[[2]]
[1] "5/1/23, 4:00 am" "Gerrard: <Media omitted>"
[[3]]
[1] "5/1/23, 4:01 am" "Gerrard: <Media omitted>"For quality control, we can count the number of elements in each split to identify where there are not 2 elements - messages that do not follow the timestamp-name-text convention, or where there are additional - in the message text, or something else we do not know about
Below shows there are messages with 2 to 6 split elements
split_counts <-
chat_split_raw |>
sapply(length)
split_counts |>
table()split_counts
2 3 4 5 6
25842 136 6 2 1 It looks like most, if not all, of the cases with 3 to 6 elements are because of multiple - in the message.
chat_raw_single[ split_counts == 3 ][1:5][1] "20/1/23, 4:01 am - Jono: Banter days are dead - Wilson is harmless lol"
[2] "16/2/23, 4:07 am - Jono: Physically - watch the goal and you'll see what i mean"
[3] "18/7/23, 12:07 pm - Gerrard: When it's against Maddison and Tottenham, Pero says Always Was Always Will Be - Change The Date"
[4] "21/7/23, 6:14 am - Jono: 2 goals in 3 matches - bitches"
[5] "27/7/23, 12:44 pm - Gerrard: Also got: Islamic Prophets Family Tree, Alien 3 - WTF Happened To This Movie?, Welcome To Stealth Camping, TalkSport, Bronze Art Warfare, 8 Out Of 10 Cats Does Countdown Highlights"chat_raw_single[ split_counts >= 4 ][1] "10/11/23, 5:09 am - Gerrard: https://youtu.be/heTMlxdiYH8?si=RI9O4FUtH__vOq1h @61452662705 All these explayers pundits missing the point about refs, saying they've never played, get explayers in to be refs, etc. The refs are mostly enforcing the letter of the law - not the \"he didn't mean it\", \"no intent\" - it's the law changes that are fucking up the games. Change the law."
[2] "15/11/23, 5:07 am - Dave: We’ve won more trophies than you both combined in the last 30 years. Arsenal - 24 Liverpool - 19 Newcastle - 0 Currently 1 point off top of the league and top of our champions league group. Exactly where we want to be. COYG 🔴 ⚪️ ❤️"
[3] "27/12/23, 11:59 pm - Dave: 8th - 5th - 2nd"
[4] "15/1/24, 10:00 pm - Dave: Arsenals starting 11 - 370m Liverpools starting 11 - 532m 162m more yet Klip is the hard done by genius let down by FSG"
[5] "20/1/24, 8:48 am - Dave: - Newtle essentially have a full strength starting 11 but blame injuries - There’s a conspiracy theory against Newtle to not let them back in top 6 because it’s bad for business - A debate is being had whether Liverpool had any meaningful injuries in 2021 - Rory Jennings is a massive clueless cunt"
[6] "8/4/24, 2:00 am - Dave: W D L 1 - 5 - 2 Title contenders @61452662705"
[7] "24/4/24, 10:01 am - James: Probably win the same amount of titles if you fold versus employing rent - a - ten hag <This message was edited>"
[8] "25/4/24, 12:31 am - Liam: Liverpool quad dream finished by: fa cup - united Europa - Atalanta PL - Everton"
[9] "28/5/24, 3:02 pm - Dave: Rice - 100m 7 goals 8 assists Mac and slob combined - 125m 8 goals 7 assists Klopps flopps, no wonder he abandoned youse" We can fix this by simply pasting the 2nd to nth elements together. We will need to do this again later, so I created a function for doing this
# Paste the 2nd to nth elements together
paste_2_nth <- function(x, collapse){
c(x[1],
paste(x[2:length(x)], collapse = collapse))
}
# Example
paste_2_nth(c('time', 'text1', 'text2'), collapse = ' - ')[1] "time" "text1 - text2"chat_split_time <-
chat_split_raw |>
lapply(FUN = paste_2_nth, collapse = ' - ')
chat_split_time |>
sapply(length) |>
table()
2
25987 Split name from text
We can split the name-text using a similar approach to above but using :. Again, if there are multiple : in a message, we will split the text multiple times, and need to paste the 2nd to nth back together (using the function we created above)
chat_split_final <-
chat_split_time |>
lapply(FUN = function(msg){
timestamp <- msg[1]
name_text <- msg[2]
# Split name and text
name_text_2 <-
name_text |>
strsplit(split = ': ') |>
lapply(FUN = paste_2_nth, collapse = ': ') |>
unlist() |>
setNames(c('name', 'text'))
# Return named 3 element vector
c(time = timestamp, name_text_2)
})chat_split_final[10:12][[1]]
time name text
"5/1/23, 3:58 am" "Gerrard" "Added JD"
[[2]]
time name text
"5/1/23, 4:00 am" "Gerrard" "<Media omitted>"
[[3]]
time name text
"5/1/23, 4:01 am" "Gerrard" "<Media omitted>" chat_split_final |>
sapply(length) |>
table()
3
25987 Create data.frame
We will work with the data in a data.frame from here on.
chat_df <-
chat_split_final |>
dplyr::bind_rows()
chat_df[10:15,]# A tibble: 6 × 3
time name text
<chr> <chr> <chr>
1 5/1/23, 3:58 am Gerrard Added JD
2 5/1/23, 4:00 am Gerrard <Media omitted>
3 5/1/23, 4:01 am Gerrard <Media omitted>
4 5/1/23, 4:02 am Gerrard <Media omitted>
5 5/1/23, 4:03 am Gerrard <Media omitted>
6 5/1/23, 4:03 am Gerrard Put some thoughts together on these, or just find a n…Cleaning names
Some of the names of messages are a result of changes to the group itself, such as changing the group name, people coming and going, etc. We need to remove these.
chat_df |>
dplyr::count(name) |>
print(n = Inf)# A tibble: 43 × 2
name n
<chr> <int>
1 "Anthony" 41
2 "Chandra" 21
3 "Chris" 300
4 "Dave" 4223
5 "Gerrard" 7962
6 "Gerrard added Dave and Liam" 1
7 "Gerrard added JD" 1
8 "Gerrard added James" 1
9 "Gerrard added you" 1
10 "Gerrard changed the group name from \"Contender Friends\" to \"Good S… 1
11 "Gerrard changed the group name from \"Good Stats Friends\" to \"Teams… 1
12 "Gerrard changed the group name from \"Negative energy only Group Chat… 1
13 "Gerrard changed the group name from \"Real EPL Chat\" to \"Real Liver… 1
14 "Gerrard changed the group name from \"Real Liverpool Pats Chat\" to \… 1
15 "Gerrard changed the group name from \"Title Challengers Group Chat + … 1
16 "Gerrard changed this group's icon" 7
17 "Gerrard created group \"Real EPL Chat\"" 1
18 "Gerrard turned off disappearing messages." 1
19 "JD" 27
20 "James" 7286
21 "James turned off disappearing messages." 2
22 "Jono" 3694
23 "Jono changed the group name from \"Title Challengers & Arsenal Fans &… 1
24 "Jono changed the group name from \"Title Challengers & Arsenal Fans G… 1
25 "Jono changed the group name from \"Weekly Refereeing Group Chat\" to … 1
26 "Jono changed this group's icon" 3
27 "Liam" 906
28 "Louie" 193
29 "Messages and calls are end-to-end encrypted. No one outside of this c… 1
30 "Pero" 1033
31 "Shaun" 192
32 "Wilson" 63
33 "You changed this group's icon" 2
34 "You updated the message timer. New messages will disappear from this … 3
35 "You're now an admin" 1
36 "~ Dave added James" 1
37 "~ Dave changed this group's icon" 4
38 "~ Dave left" 1
39 "~ James changed the group name from \"Auf Wiedersehen Klapp\" to \"Co… 1
40 "~ James changed the group name from \"Title Challengers & Arsenal Fan… 1
41 "~ James changed this group's icon" 2
42 "~ James left" 1
43 "~ Liam Keepence added Dave" 1We can match those “names” we do not want
chat_df_clean <-
chat_df |>
dplyr::filter(!grepl(' added |left$| changed | created |^Messages|an admin$|messages.$| message timer', name))Now we have only true messages from people in the group
chat_df_clean |>
dplyr::count(name) |>
print(n = Inf)# A tibble: 13 × 2
name n
<chr> <int>
1 Anthony 41
2 Chandra 21
3 Chris 300
4 Dave 4223
5 Gerrard 7962
6 JD 27
7 James 7286
8 Jono 3694
9 Liam 906
10 Louie 193
11 Pero 1033
12 Shaun 192
13 Wilson 63Cleaning messages
When we choose to exlcude media in the Whatapp export, it still exports that a message was created but with the text "<Media omitted>". We want to remove such messages.
chat_df_clean |>
dplyr::count(text, sort = T) |>
print(n = 20)# A tibble: 24,126 × 2
text n
<chr> <int>
1 "<Media omitted>" 646
2 "Lol" 66
3 "Wow" 64
4 "This message was deleted" 25
5 "🤣" 24
6 "\U0001fa87" 24
7 "?" 22
8 "Yep" 21
9 "😂" 19
10 "Ouch" 17
11 "Racist" 17
12 "True" 14
13 "Yeah" 14
14 "🤣🤣🤣" 14
15 "No" 13
16 "💯" 13
17 "🤷🏼♂️" 13
18 "Exactly" 12
19 "Yes" 12
20 "lol" 12
# ℹ 24,106 more rowschat_df_clean <-
chat_df_clean |>
dplyr::filter(!text %in% c("<Media omitted>", "This message was deleted"))We also want to remove "<<This message was edited>" from text
chat_df_clean |>
dplyr::filter(grepl('<This message was edited>', text))# A tibble: 299 × 3
time name text
<chr> <chr> <chr>
1 23/8/23, 3:23 am Dave But hendos a hero? <This message was edited>
2 23/8/23, 5:56 am Dave And? Brentford snapped it up, small club. You don’t …
3 1/9/23, 10:08 pm Dave As a neutral I was questioning the Saudi link and ge…
4 11/9/23, 1:02 am James I wonder why a more successful club hasn't come in f…
5 21/9/23, 7:44 pm Dave Such an “almost” striker isn’t he. He’s got to have …
6 25/9/23, 2:36 am Dave Not rice <This message was edited>
7 5/10/23, 4:13 am James @61409710717 do you think if you get the spurs game …
8 5/10/23, 4:27 am James Same CLs as Chelsea who I assume you both think are …
9 7/10/23, 10:49 am James @14244893404 is there an asterisk on everything Varp…
10 8/10/23, 11:33 pm James Should have beat West Ham too but one point is good …
# ℹ 289 more rowschat_df_clean <-
chat_df_clean |>
dplyr::mutate(text = sub(' <This message was edited>$', '', text))
chat_df_clean |>
dplyr::filter(grepl('<This message was edited>', text))# A tibble: 0 × 3
# ℹ 3 variables: time <chr>, name <chr>, text <chr>Split message text into words
We will split words using a space . This will create a list column (since we are using tibbles). We unnest the list column to have the words of a message still associated with the name of the person. And then convert all text to lower case
chat_words <-
chat_df_clean |>
dplyr::mutate(word = strsplit(text, split = ' ')) |>
dplyr::select(!text) |>
tidyr::unnest(cols = word) |>
dplyr::mutate(word = tolower(word))chat_words# A tibble: 192,250 × 3
time name word
<chr> <chr> <chr>
1 5/1/23, 3:55 am Gerrard putting
2 5/1/23, 3:55 am Gerrard the
3 5/1/23, 3:55 am Gerrard other
4 5/1/23, 3:55 am Gerrard chat
5 5/1/23, 3:55 am Gerrard on
6 5/1/23, 3:55 am Gerrard mute
7 5/1/23, 3:55 am Gerrard and
8 5/1/23, 3:55 am Gerrard seeing
9 5/1/23, 3:55 am Gerrard how
10 5/1/23, 3:55 am Gerrard it
# ℹ 192,240 more rowsCleaning words
Remove stop words, HTTP links, clean punctuation and emojis.
chat_words |>
dplyr::count(word, sort = TRUE)# A tibble: 19,526 × 2
word n
<chr> <int>
1 the 6522
2 a 4187
3 to 3560
4 and 2876
5 in 2541
6 i 2388
7 you 2220
8 of 2166
9 is 1945
10 that 1762
# ℹ 19,516 more rows# Include grammatically incorrect stop words from the tidytext list of stop words
# e.g. don't and dont, i'll and ill
my_stop_words <-
dplyr::bind_rows(
tidytext::stop_words,
dplyr::mutate(tidytext::stop_words, word = gsub('[[:punct:]]+', '', word))
) |>
dplyr::distinct(word)
# Remove HTTP links, clean punctuation and stop words
chat_words_clean <-
chat_words |>
dplyr::filter(!grepl('^@|^http', word)) |>
dplyr::mutate(word = gsub('[[:punct:]]+', '', word)) |>
dplyr::filter(word != '') |>
dplyr::filter(!grepl('^[[:digit:]]+$', word)) |>
dplyr::anti_join(my_stop_words, by = 'word')There are also emojis in the text. These are annoying to deal with, especially when there are multiple ones together without a space. We will just take the first one if there are many
chat_words_clean |>
dplyr::filter(emoji::emoji_detect(word))# A tibble: 183 × 3
time name word
<chr> <chr> <chr>
1 6/2/23, 11:56 am Jono 🧹
2 1/5/23, 2:53 am Pero 🤫
3 15/6/23, 2:55 pm Jono 🥵
4 19/6/23, 4:54 am Chris 🥳
5 9/8/23, 4:33 am James 🧑🧑
6 11/8/23, 7:14 am Shaun 🤟🥳
7 12/8/23, 12:02 pm Anthony 🥳🥳🥳🥳🥳🥳🥳🥳🥳🥳🥳🥳🥳🥳🥳🥳🥳🥳
8 12/8/23, 3:08 pm Jono 🤌
9 14/8/23, 10:55 pm Jono 🫡
10 16/8/23, 1:20 pm Chris 🤯
# ℹ 173 more rowschat_words_clean_emoji <-
chat_words_clean |>
dplyr::mutate(word = dplyr::case_when(
emoji::emoji_detect(word) ~ emoji::emoji_fix(substr(word, 1,1)),
.default = word
))
chat_words_clean_emoji |>
dplyr::filter(emoji::emoji_detect(word))# A tibble: 183 × 3
time name word
<chr> <chr> <chr>
1 6/2/23, 11:56 am Jono 🧹
2 1/5/23, 2:53 am Pero 🤫
3 15/6/23, 2:55 pm Jono 🥵
4 19/6/23, 4:54 am Chris 🥳
5 9/8/23, 4:33 am James 🧑
6 11/8/23, 7:14 am Shaun 🤟
7 12/8/23, 12:02 pm Anthony 🥳
8 12/8/23, 3:08 pm Jono 🤌
9 14/8/23, 10:55 pm Jono 🫡
10 16/8/23, 1:20 pm Chris 🤯
# ℹ 173 more rowsThus our final word counts looks something like this
chat_words_clean_emoji |>
dplyr::count(word, sort = TRUE)# A tibble: 10,863 × 2
word n
<chr> <int>
1 arsenal 744
2 season 674
3 liverpool 590
4 game 565
5 league 518
6 team 500
7 win 492
8 lol 449
9 shit 387
10 fans 374
# ℹ 10,853 more rowsFinal clean data
We create two objects
- chat_text_final: timestamp, name, message text
- chat_words_final: timestamp, name, words in text
chat_text_final <- chat_df_clean
chat_words_final <- chat_words_clean_emoji
chat_text_final# A tibble: 25,270 × 3
time name text
<chr> <chr> <chr>
1 5/1/23, 3:55 am Gerrard Putting the other chat on Mute and seeing how it tak…
2 5/1/23, 3:56 am Gerrard Think we should have a catch over a game sometime, i…
3 5/1/23, 3:57 am Chris Lol. Silly English.
4 5/1/23, 3:58 am Chris Made John disappear. Maybe add him back to this one?
5 5/1/23, 3:58 am Gerrard Added JD
6 5/1/23, 4:03 am Gerrard Put some thoughts together on these, or just find a …
7 5/1/23, 8:31 am Shaun Nobody watches the EPL, it's a second rate league
8 5/1/23, 8:32 am Gerrard Football League One is where it's at
9 5/1/23, 8:37 am Shaun Can someone stream the game so we can all watch 😅
10 5/1/23, 9:33 am Jono I’m in. Let’s lock in a date
# ℹ 25,260 more rowschat_words_final# A tibble: 73,471 × 3
time name word
<chr> <chr> <chr>
1 5/1/23, 3:55 am Gerrard putting
2 5/1/23, 3:55 am Gerrard chat
3 5/1/23, 3:55 am Gerrard mute
4 5/1/23, 3:55 am Gerrard takes
5 5/1/23, 3:55 am Gerrard english
6 5/1/23, 3:55 am Gerrard notice
7 5/1/23, 3:56 am Gerrard catch
8 5/1/23, 3:56 am Gerrard game
9 5/1/23, 3:57 am Chris lol
10 5/1/23, 3:57 am Chris silly
# ℹ 73,461 more rowsVisualisations
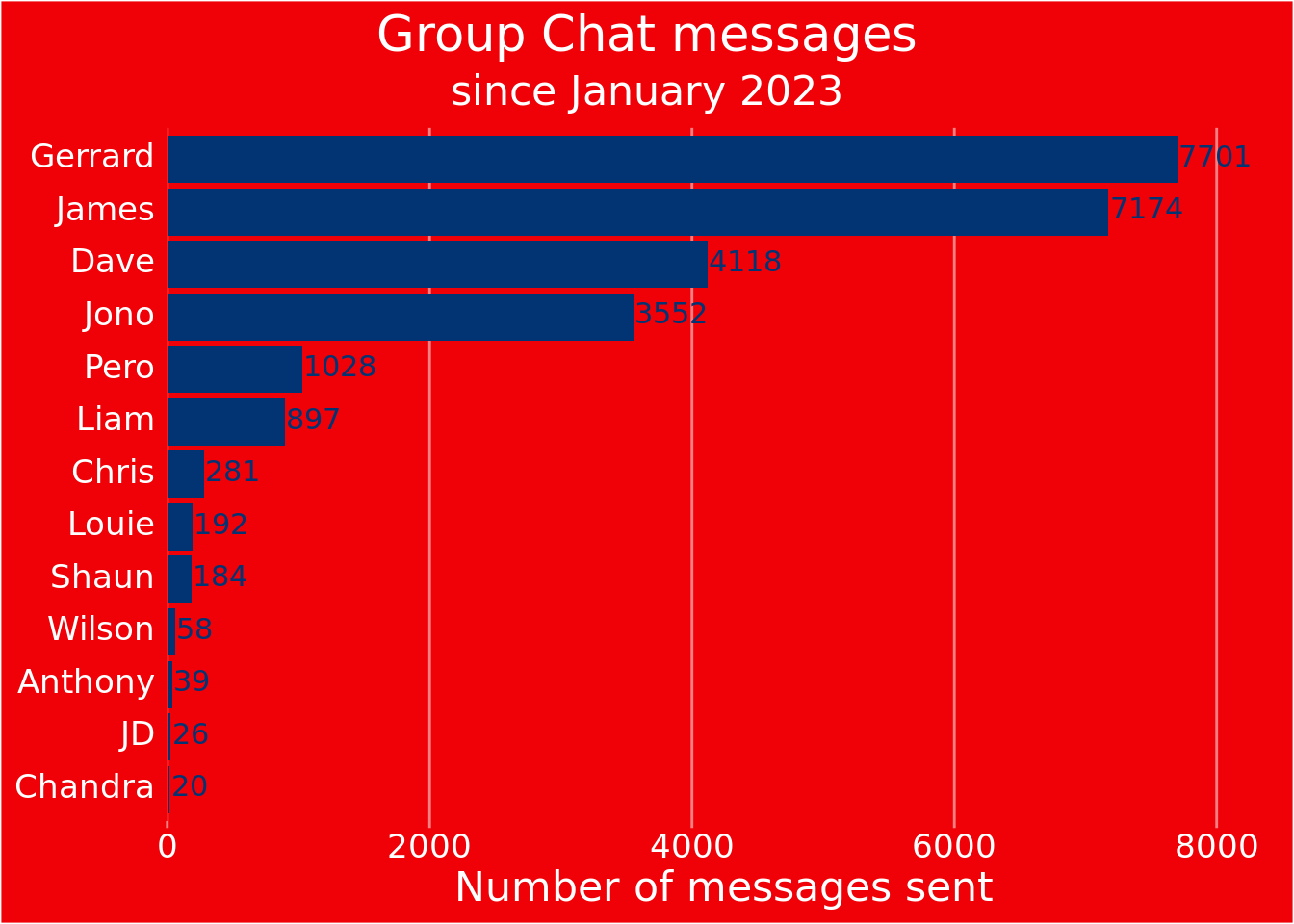
The number of messages by person
By creating a colour scheme object, we can easily shift between team colours for the plot. Here we will use Arsenal colours, but note the Liverpool once exits.
# Arsenal
brand_colours <-
list(
main = "#EF0107",
sub = "#023474",
supp = "#9C824A",
white = "white"
)
# # Liverpool
# brand_colours <-
# list(
# main = "#C8102E",
# sub = "#00B2A9",
# supp = "#F6EB61",
# white = "white"
# )
chat_text_final |>
dplyr::count(name) |>
dplyr::arrange(n) |>
dplyr::mutate(name = factor(name, levels = name)) |>
ggplot(aes(y = name, x = n)) +
geom_col(fill = brand_colours$sub) +
geom_text(aes(label = n), color = brand_colours$sub, hjust = 0, nudge_x = 10, size = 4,
vjust = 0.33) +
labs(title = 'Group Chat messages',
subtitle = 'since January 2023',
y= NULL,
x = 'Number of messages sent') +
scale_x_continuous(expand = expansion(mult = c(0, 0.1))) +
theme(
text = element_text(colour = brand_colours$white, size = 16),
axis.text = element_text(colour = brand_colours$white),
axis.ticks = element_line(colour = scales::alpha(brand_colours$white, 0.5)),
axis.ticks.y = element_blank(),
axis.text.y = element_text(vjust = 0.35),
plot.background = element_rect(fill = brand_colours$main),
panel.background = element_rect(fill = brand_colours$main),
plot.title.position = 'plot',
plot.title = element_text(hjust = 0.5),
plot.subtitle = element_text(hjust = 0.5),
panel.grid.major.y = element_blank(),
panel.grid.major.x = element_line(colour = scales::alpha(brand_colours$white, 0.5)),
panel.grid.minor.x = element_blank(),
)
Word cloud
We first need to count the words
chat_words_count <-
chat_words_final |>
dplyr::count(word, sort = T)And create a default word cloud function
wordcloud_default <- function(data, max.words, title){
wordcloud::wordcloud(
words = data$word,
freq = data$n,
scale = c(3, 0.5), # Set min and max scale
max.words = max.words, # Set top n words
random.order = FALSE, # Words in decreasing freq
random.color = TRUE,
rot.per = 0, # % of vertical words
use.r.layout = FALSE, # Use C++ collision detection
colors = unlist(brand_colours[c('main', 'main', 'sub', 'sub', 'supp')]))
if (!missing(title)){
text(x = 0.5, y = 1, labels = title)
}
}set.seed(1010)
par(mar = rep(0, 4))
wordcloud_default(chat_words_count, max.words = 100)
chat_words_count_gerrard <-
chat_words_final |>
dplyr::filter(name == "Gerrard") |>
dplyr::count(word, sort = T)
chat_words_count_james <-
chat_words_final |>
dplyr::filter(name == "James") |>
dplyr::count(word, sort = T)
# The plot
par(mfrow = c(1,2), mar = rep(0,4))
wordcloud_default(chat_words_count_gerrard,
max.words = 50,
title = 'Gerrard')
wordcloud_default(chat_words_count_james,
max.words = 50,
title = 'James')